Continuous integration: quando la pratica va oltre gli strumenti

Giorgio
DevelopmentChe cos’è la continuous integration ?
Martin Fowler nel suo articolo spiega:
Continuous integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily – leading to multiple integrations per day. each integration is verified by an automated build (including test) to detect integration errors as quickly as possible. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly.
Da queste poche righe si apre la finestra verso un mondo: fowler non parla di strumenti o tecnologie, bensì di pratica.
Il problema dell’integrazione non è banale: quando due o più sviluppatori lavorano contemporaneamente sullo stesso progetto non è raro che, al momento di mettere tutto insieme, si presentino problemi come conflitti o incompatibilità. Troppo spesso si assiste allo scenario in cui la data di consegna al cliente è vicina ed il software è più o meno pronto: << manca solo l’integrazione finale e gli ultimi fix >>, si direbbe, così facendo però solitamente ci si imbuca in un tunnel dentro il quale difficilmente si farà un bel viaggio, ma soprattutto sarà impossibile conoscerne a priori la lunghezza.
I bug e gli imprevisti sono per definizione non stimabili, né in numero né in complessità di risoluzione: come pretendere di stimare un tempo di integrazione, quando non si ha nemmeno una predizione a livello locale dei problemi emersi ? Siamo finiti nel tunnel, nell’integration hell: la scadenza è sempre più vicina e non abbiamo idea di quando il software sarà correttamente funzionante. Lo stress nel team aumenta con l’avvicinarsi della deadline, si rimane in ufficio fino a tardi e la stanchezza ed il malumore accumulati portano inevitabilmente all’introduzione di nuovi bug per risolvere quelli precedenti.
È proprio nel momento di mettere tutto insieme che la continuous integration interviene: l’integrazione del software non dovrebbe avvenire alla conclusione del processo di sviluppo, in cui tutti i problemi vengono identificati e risolti in una sola volta, ma dovrebbe essere parte di questo processo ed intervenire continuamente. La motivazione di ciò è semplice: rendere questo processo continuo limita il numero e la gravità degli errori rilevati, perché effettuare piccoli cambiamenti ed integrarli subito significa dover correggere al più bug recenti e non interi moduli dipendenti da anomalie introdotte molto tempo indietro e mai rilevate.
Vediamo ora le pratiche fondamentali che ci permettono di fare continuous integration correttamente e come esse influenzeranno il nostro processo di sviluppo.
Utilizzare un version control repository
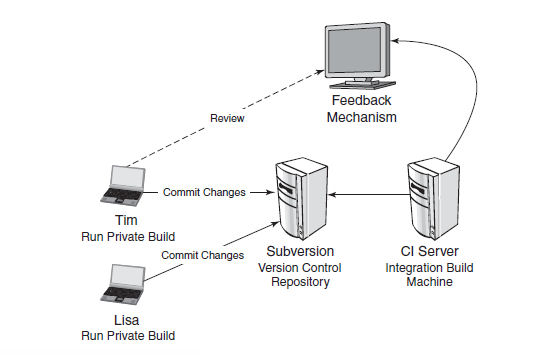
L’utilizzo di un sistema di controllo di versione come subversion, git o CVS è il primo mattone con il quale costruire il nostro ambiente di continuous integration. Tralasciando le differenze che i vari sistemi di controllo di versione hanno tra loro, è di fondamentale importanza avere un “repository” che permetta di gestire e monitorare i cambiamenti che avvengono sulla nostra code base. In questo modo si ha inoltre la possibilità di effettuare rollback dei cambiamenti: tramite strumenti di questo tipo infatti viene tenuta traccia della storia di ogni file.
Nel repository deve essere presente tutto il necessario
Non meno importante è l’avere tutto il nostro software, compresi framework, librerie e dipendenze esterne, all’interno del nostro repository: esso dovrà fungere da unica fonte del codice ed il nostro software dovrà essere in grado di funzionare solamente con quello che vi è contenuto, senza interventi esterni o aggiunte manuali.
Eseguire una “commit” almeno una volta al giorno
Come regola empirica, ci si impone di inviare il proprio lavoro al repository almeno una volta al giorno, anche se è vivamente consigliato puntare ad un numero di integrazioni maggiore. Questo è necessario per rispettare il principio dei piccoli cambiamenti precedentemente introdotto. Naturale conseguenza di ciò è la suddivisione del proprio lavoro in piccoli task atomici, che favorisce inoltre la scrittura di un codice più snello, pulito e mediamente privo di inutili complessità. in una sola parola, rispettare il KISS principle.
Automatizzare le build
Il processo di build non è solo la compilazione del codice (che non sempre avviene, come ad esempio nel linguaggio PHP) ma significa compiere un determinato numero di azioni che permettono al software di essere correttamente “costruito” e reso funzionante. rendere questo insieme di passi automatico attraverso un singolo script di building (come ant o phing) porta con sé vari vantaggi. Primo: limita l’intervento umano e di conseguenza la probabilità di errori ed omissioni (lo sviluppatore lancia un singolo comando “build”). Secondo, ma non meno importante: la riproducibilità ottenuta che permetterà a tutti gli sviluppatore di eseguire gli stessi passaggi in maniera identica (a meno di eventuali parametri di configurazione) mitigando la famosa, odiata frase “but it works on my machine”.
Self testing build
Non si fa continuous integration senza scrivere test automatici. tali test devono essere inoltre inglobati nei build script. A build completata lo sviluppatore conoscerà il risultato del proprio lavoro e solo tramite test automatici sarà in grado di averne confidenza sulla bontà. Non è pensabile eseguire tali test manualmente perché inevitabilmente qualcosa prima o poi verrà omesso, soprattutto nel modello di sviluppo che stiamo introducendo, in cui il software viene integrato (e quindi necessita di essere ritestato) ad ogni cambiamento.
È facile dire “il modulo b non necessita di essere testato perché ho modificato solo il modulo a” ma quante volte, nella realtà, sono emersi problemi derivanti da certe assunzioni? I test automatici sono la nostra rete di salvataggio e sono perfettamente riproducibili: ad ogni build ritesteranno tutte le funzionalità per cui sono stati scritti, più velocemente e più affidabilmente di qualsiasi sviluppatore o team, anche il più volenteroso, veloce e competente. nessuno riuscirà mai ad eseguire un gran numero di volte la stessa batteria di test senza ogni volta introdurre piccole differenze, soprattutto a fine giornata, quando la stanchezza si fa sentire. I build script, invece, non si stancano, usiamoli.
Eseguire delle build private nelle workstation locali
Ogni sviluppatore dovrà scaricare dal repository l’ultima versione del software che sta sviluppando. a questo punto lavorerà nella propria macchina locale, effettuando i cambiamenti necessari per il proprio lavoro. una volta terminati dovrà effettuare la build del software sulla propria workstation ed osservarne i risultati. Se tutto funziona correttamente, prima di inviare il proprio codice al repository, scaricherà da questo gli eventuali cambiamenti effettuati nel frattempo dagli altri sviluppatori e rilancerà di nuovo la build. Se tutto va a buon fine, è stato fatto un primo passo verso l’integrazione: i propri cambiamenti sono stati integrati ed è possibile aggiornare la code-base eseguendo la “commit”.
Non inviare codice difettoso al repository
In caso di fallimento dei test durante la build locale lo sviluppatore dovrà correggere i malfunzionamenti e ri-eseguire la build fino alla risoluzione dei problemi. Non potrà, in nessun caso, inviare il proprio lavoro al repository se i test non certificano che esso è correttamente integrato.
In questo modo si minimizza la probabilità di avere software non funzionante nel repository: la copia “rotta” resterà confinata nella macchina dello sviluppatore che si occuperà di sistemarla.
Eseguire una build di integrazione ad ogni cambiamento
Ogni volta che il repository viene aggiornato con nuovi cambiamenti, il codice necessita di essere ritestato. Successivamente alle build private, si eseguono quindi delle build di integrazione, che devono essere effettuate su di una macchina dedicata, che riproduca il più fedelmente possibile il vero ambiente di produzione. È importantissimo, inoltre, che questa ultima macchina sia priva di dipendenze e librerie spurie che non provengano direttamente dal repository: in questo modo ci si accerta che il lavoro dello sviluppatore sia ancora riproducibile e non dipenda da una sua particolare configurazione a livello locale.
L’integration build può essere manuale o effettuata automaticamente tramite un continuous integration server (come hudson o cruisecontrol). Sebbene quest’ultimo componente non sia obbligatorio, è comunque raccomandato usarne uno: sarà lui per noi a rilevare i cambiamenti sul repository ed eseguire le build automaticamente, fornendo inoltre una comoda dashboard con report sui test, code coverage, strumenti di analisi aggiuntivi e documentazione auto-generata.
Non scaricare codice difettoso dal repository, riparare immediatamente le build rotte
Nella malaugurata ipotesi in cui la build di integrazione fallisca, nonostante siano state correttamente passate le build private, sorge il problema della “broken build”: è entrato un bug nel codice del repository e tutti coloro che andranno a scaricarlo otterrebbero del software non funzionante. È compito dell’ultimo sviluppatore che ha eseguito la commit risolvere il problema, ma visto che questo malfunzionamento coinvolge tutto il team è meglio non scaricare affatto il codice difettoso: invece che perdere tempo nello sviluppo di eventuali workaround è preferibile aiutare gli altri a far tornare la build nello status di “green”.
Build veloci e rapid feedback
È importante che il processo di build sia veloce e rapido: non è accettabile attendere più 10 minuti per il risultato dei nostri test (regola del “10 minute build”), altrimenti si perderà troppo tempo per via delle molteplici integrazioni o peggio ancora lo sviluppatore tenderà ad accumulare molto codice prima di lanciare i test. Per evitare questo anti pattern è consigliabile quindi eseguire delle staged-build ossia lanciare le build private accompagnate solamente da test leggeri (unitari) e le build di integrazione divise in due: test unitari prima (per individuare subito problemi grossolani) per le build lanciate ad ogni commit e test più approfonditi (unitari e funzionali, analisi del codice, delle dipendenze, del code-style ecc) per build lanciate in un successivo momento, magari schedulate in notturna (nightly build) o in seguito al successo delle precedenti commit-build.
In questo modo si ottiene un feedback immediato che deve essere coadiuvato da meccanismi che lo rendano facilmente individuabile e interpretabile: una lampada sempre verde che diventa rossa in caso di build rotta è uno degli esempi più tipici. È importante che il feedback sia incentrato sulle informazioni utili ed essenziali, tutto il superfluo tenderà a distrarre lo sviluppatore, che nella confusione rischia di ignorare messaggi importanti.
I pro ed i contro
Il rispetto di una pratica richiede un iniziale costo dovuto dalla intrinseca curva di apprendimento che presenta. test automatici e buone pratiche di programmazione hanno un costo in termini di tempo, come pure l’acquisto e l’uso di macchine dedicate per simulare l’ambiente di produzione; tutto questo, nel brevissimo termine, potrebbe essere visto come un overhead. Tali costi verranno però ampiamente ripagati durante il ciclo di sviluppo del nostro software. Ne beneficerà la qualità del codice sviluppato: grazie al testing continuo infatti si ha sempre la certezza che niente è andato storto. Ansia e stress caleranno: se tutto quel che viene scritto è sempre attestato come funzionante da opportuni test, automaticamente cala anche la paura di andare incontro a imprevisti ed inconvenienti. La comunicazione all’interno del team aumenterà: grazie al feedback rapido e condiviso, tutti sanno a che punto è lo sviluppo del software, quali sono i problemi emersi e le funzionalità ancora da implementare. Anche il rapporto con il cliente trarrà dei benefici: la maggior tranquillità e sicurezza sul progetto verranno percepite come sintomo di puntualità e professionalità. ultima ma non meno importante è infine la possibilità di poter effettuare continui rilasci di nuove versioni del nostro software: nel repository infatti è presente in ogni momento software perfettamente funzionante e quindi “deployable”.
Questione di pratica
In questa introduzione abbiamo parlato di buone pratiche (tante) e citato alcuni strumenti (pochi) per mettere in piedi un ambiente di continuous integration. È infatti sulle pratiche di sviluppo il vero investimento che un team di lavoro dovrebbe sostenere, perché dietro a tutte le tecnologie, anche le più valide e promettenti, ci sono sempre le persone. La continuous integration ne prende atto, facendosi carico di tutti quei compiti che rendono dura la vita dello sviluppatore, che potrà dedicarsi finalmente a compiti di più alto livello e alla vera business logic di progetto.
Una miglior comunicazione tra stakeholders ed un ambiente mitigato da ansia e stress sono i primi ingredienti per vivere ogni progetto come una nuova sfida, vissuta con proattività e voglia di fare: non dimentichiamo mai che il software, benché eseguito da macchine, è sempre scritto da persone 🙂
Per chi volesse approfondire consiglio la lettura dell’articolo originale dal sito di martin fowler ma soprattutto dell’ottimo libro “Continuous Integration: Improving Software Quality and Reducing Risk” (http://www.integratebutton.com/).