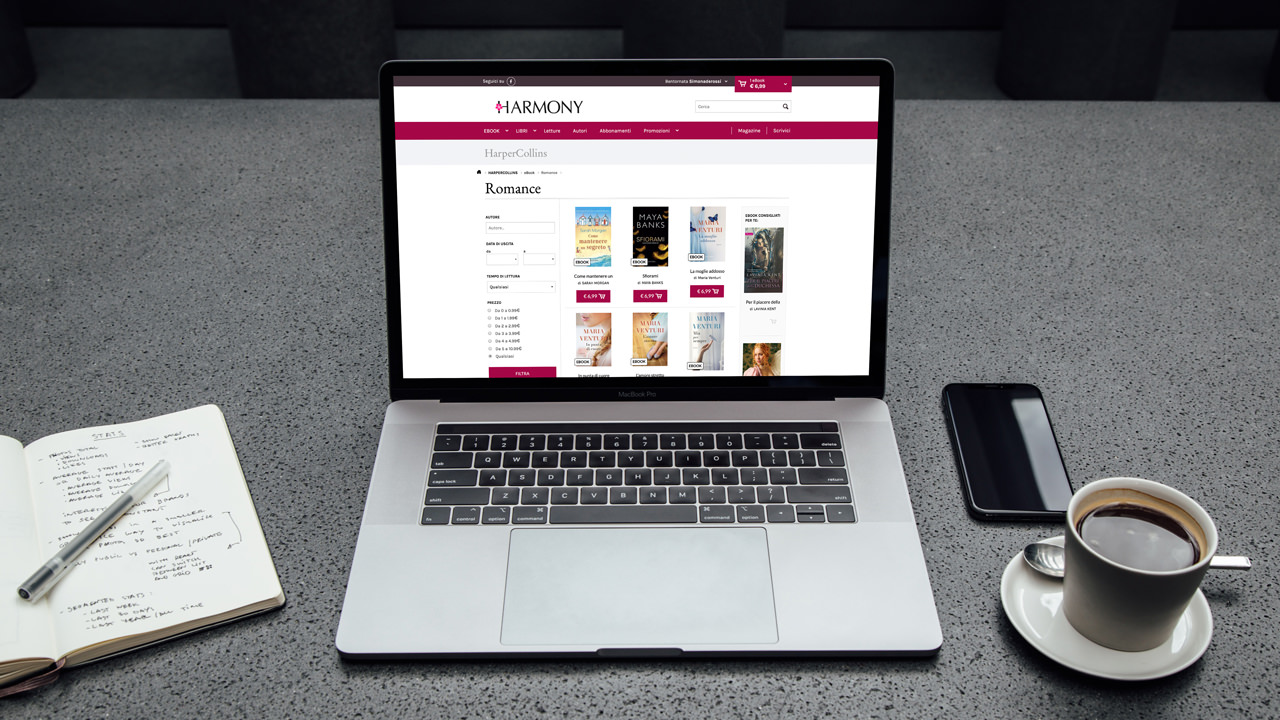
Harmony è un brand di HarperCollins Italia, casa editrice la cui missione è pubblicare libri di qualità che intrattengano e ispirino i lettori.
Con una produzione di circa 600 titoli l’anno, Harmony tocca tutte le sfumature del Romance accontentando milioni di fedelissime lettrici.
Proprio questa abbondanza di prodotti ha spinto HarperCollins Italia a chiederci – a seguito della collaborazione instaurata dal 2008 – di progettare un sistema di suggerimenti automatici da integrare all’e-commerce dedicato ai romanzi Harmony, che consigliasse agli utenti nuovi libri da acquistare secondo il loro gusto, ovvero studiando il loro storico di lettori e ricercando tra i prodotti quelli più attinenti alle inclinazioni dell’utente.
Il libro giusto per te
Non solo refactoring della piattaforma ma anche innovazione: nel 2014 abbiamo avviato la progettazione di un sistema di suggerimenti automatico da integrare all’e-commerce di Harmony.
I sistemi di raccomandazione sono una tipologia di sistemi di filtraggio delle informazioni che cercano di prevedere la valutazione o la preferenza che l’utente potrebbe dare ad un elemento. Sono diventati molto comuni in questi ultimi anni e sono utilizzati da una vasta gamma di applicazioni, le più popolari riguardano film, musica, notizie, libri, articoli di ricerca e tag di social networking. Tuttavia, ci sono anche sistemi di raccomandazione per i ristoranti, servizi finanziari, assicurazioni sulla vita e persone (siti di appuntamenti online, seguaci di Twitter). Questi sistemi, tuttora oggetto di studi, sono già applicati in un’ampia gamma di settori, come ad esempio le piattaforme di scoperta dei contenuti, utilizzate on-line per aiutare gli utenti nella ricerca di trasmissioni televisive; oppure i sistemi di supporto alle decisioni che utilizzano sistemi di raccomandazione avanzati, basati sull’apprendimento delle conoscenze, per aiutare i fruitori del servizio nella soluzioni di problemi complessi. Inoltre, i sistemi di raccomandazione sono una valida alternativa agli algoritmi di ricerca in quanto aiutano gli utenti a scoprire elementi che potrebbero non aver trovato da soli. Infatti, sono spesso implementati utilizzando motori di ricerca che indicizzano dati non tradizionali.
Sistemi a filtraggio collaborativo
In generale, il filtraggio collaborativo è il processo di filtraggio di informazioni o modelli che utilizzano tecniche che includono la collaborazione tra più agenti, punti di vista, fonti di dati, ecc. Le applicazioni di filtraggio collaborativo coinvolgono solitamente grandi insiemi di dati. Metodi di filtraggio collaborativi sono stati applicati in diverse situazioni, tra cui: rilevamento e monitoraggio dei dati, rilevamento ambientale su aree estese o più sensori; dati finanziari, come ad esempio gli istituti di servizi finanziari che integrano diverse fonti finanziarie; in e-commerce e applicazioni web dove il focus sono i dati degli utenti. In senso stretto, invece, il filtraggio collaborativo è un metodo per effettuare previsioni automatiche circa gli interessi di un utente, raccogliendo le preferenze o le valutazioni da molti altri utenti.
Gli algoritmi di filtraggio collaborativo richiedono: partecipazione attiva, un modo semplice di rappresentare gli interessi degli utenti al sistema, e algoritmi che siano in grado di abbinare persone con interessi simili. Il flusso di lavoro di un sistema di filtraggio collaborativo è articolato come segue:
- un utente esprime le sue preferenze valutando gli elementi del sistema (ad esempio film, CD o libri, come nel caso di Harmony). Queste valutazioni possono essere viste come una rappresentazione approssimativa dell’interesse dell’utente nel dominio corrispondente;
- il sistema abbina le valutazioni dell’utente con quelle degli altri utenti del sistema e trova le persone con gusti simili a quelli dell’utente attivo;
- il sistema suggerisce all’utente attivo elementi su cui non ha ancora espresso una preferenza ma che i suoi simili hanno valutato positivamente (l’assenza di valutazione è spesso considerata come la scarsa conoscenza di un oggetto).
I sistemi di filtraggio collaborativo hanno molte forme, ma generalmente le loro funzioni possono essere schematizzate in due fasi che, nel filtraggio basato sulla somiglianza tra utenti, corrispondono a:
- cercare gli utenti che condividono gli stessi modelli di valutazione con l’utente per cui si vuole generare la raccomandazione;
- utilizzare i feedback provenienti dagli utenti simili per calcolare una previsione per l’utente attivo.
Diversamente, il filtraggio collaborativo tra oggetti procede in maniera centralizzata all’elemento:
- viene costruita una matrice elemento-elemento che determina le relazioni tra coppie di elementi;
- vengono dedotti i gusti dell’utente corrente esaminando la matrice, abbinandola alle informazioni dell’utente.
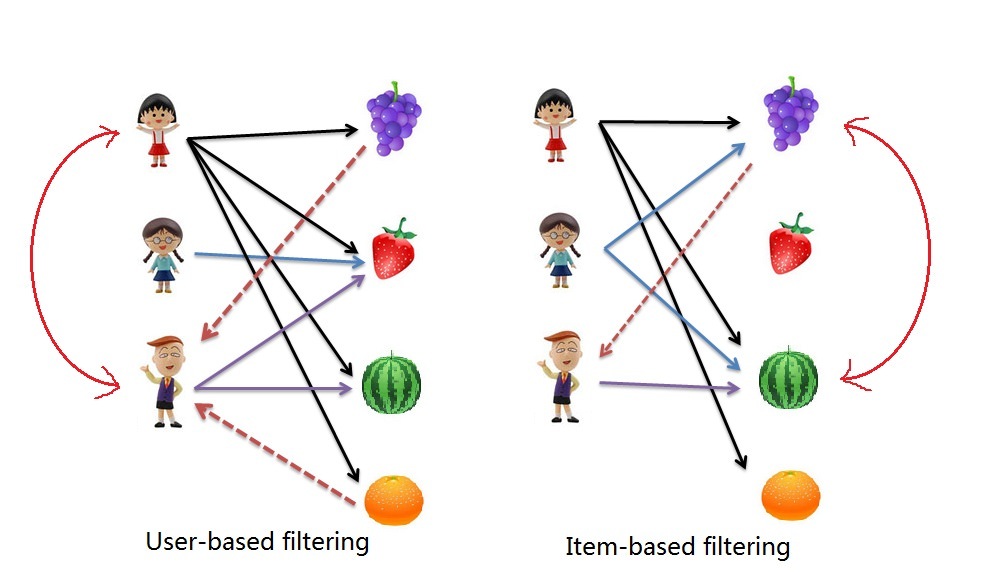
Un’altra forma di filtraggio collaborativo può essere basata su osservazioni implicite del normale comportamento degli utenti, in contrapposizione al comportamento artificiale imposto dall’attività di valutazione. Questi sistemi osservano lo azioni svolte da un utente insieme a ciò che hanno fatto tutti gli altri utenti (la musica che hanno ascoltato, quali libri hanno comprato), e utilizzano tali dati per prevedere il comportamento futuro dell’utente o per suggerire elementi potrebbero piacergli. Questo tipo di filtraggio collaborativo è detto implicito poiché l’utente non effettua nessuna operazione diretta che possa influire sulle raccomandazioni ottenute. La motivazione principale per tracciare implicitamente le preferenze dell’utente consiste nel fatto di eliminare per quest’ultimo il costo ed il tempo di esaminare e valutare l’articolo, mentre rimane un costo computazionale di memorizzazione e di elaborazione dei dati impliciti, che però può essere nascosto all’utente. Potenzialmente, ogni interazione dell’utente con il sistema genererà dati impliciti e di fatto si potrebbe arrivare ad una situazione con troppi dati, piuttosto che la scarsità incontrata da approcci di valutazione espliciti. Ogni valutazione implicita sarà meno potente di una valutazione esplicita, ma il numero di valutazioni implicite ottenibili è nettamente maggiore al numero di quelle esplicite, perciò un approccio di questo tipo può risultare più efficace, oltre che più economico in termini di tempo e di progettazione. Le previsioni ottenute in questo modo dovranno essere filtrate attraverso una logica di business per determinare in che modo possano influenzare le azioni di un sistema aziendale. Ad esempio, non è utile suggerire l’acquisto di un particolare album musicale se l’utente ha già dimostrato di possederlo.
Il sistema progettato per Harmony
Sulla piattaforma di Harmony, al momento del suo rilancio, non era presente un sistema di raccomandazione automatico: i suggerimenti mostrati agli utenti erano un elenco degli articoli più venduti. Si è quindi deciso di implementare un sistema di raccomandazione per automatizzare e diversificare i suggerimenti: l’obiettivo è quello di suggerire elementi simili a quelli acquistati oltre ad elementi di alto gradimento all’interno della piattaforma. Per raggiungere tale obiettivo si è scelto di sfruttare PredictionIO, un server di Machine Learning – ora parte del gruppo Apache – che utilizza i filtri collaborativi per effettuare le raccomandazioni.
Per velocizzare il processo di raccolta dati e per rendere trasparente all’utente la presenza del motore di raccomandazioni, abbiamo scelto di implementare un sistema di valutazione implicito. Seguendo le logiche di business del cliente abbiamo assegnato un valore, in una scala da 1 a 5, alle azioni di nostro interesse che vengono svolte sull’e-commerce.
Ed esempio la visualizzazione della pagina di un romanzo ha un valore inferiore all’aggiunta in wishlist dell’elemento, e l’aggiunta del prodotto al carrello ha un valore ancora maggiore. Il completamento dell’acquisto è l’azione col punteggio più alto.
Tutti questi valori vengono salvati e associati in una tabella utente-prodotto, che le Engine di PredictionIO utilizzano per:
- determinare il grado di “somiglianza” tra due prodotti, quindi per suggerire prodotti associati;
- individuare utenti con preferenze simili e suggerire acquisti basati su quando apprezzato dagli utenti identificati.
Come molti i sistemi di raccomandazione, tra cui i sistemi a filtraggio collaborativo, il problema della partenza a freddo su Harmony è stato evidente. C’erano troppi pochi dati per poter suggerire qualcosa di realmente personalizzato, gli utenti visualizzavano gli stessi contenuti. Per ovviare a questo inconveniente noto, abbiamo scelto di raccogliere i dati senza mostrare suggerimenti per i primi due mesi dopo il rilancio della piattaforma. Questo periodo è stato sufficiente per ottenere una mole di dati tale da diversificare i suggerimenti tra gli utenti. Abbiamo quindi aggiunto all’elenco delle nuove uscite e dei libri acquistati i suggerimenti ottenuti dal sistema di raccomandazioni, inserendo tale informazione nelle pagine di dettaglio dei romanzi, nelle pagine dedicate alle categorie e inviando i suggerimenti anche tramite newsletter.
Questo scenario apre a nuovi sviluppi come ad esempio:
- l’esclusione dai suggerimenti degli acquisti già effettuati;
- l’esclusione dei romanzi attualmente non disponibili e la notifica di quelli nuovamente acquistabili;
- il tracciamento delle sessioni degli utenti non loggati sull’ecommerce di Harmony, con conseguente trasferimento dei dati raccolti al loro profilo in caso di login;
- inserimento di valutazioni esplicite da parte dell’utente come ad esempio la valutazione del romanzo, al fine di migliorare il sistema di raccolta dati e la conseguente elaborazione dei suggerimenti.
Evoluzione di una codebase legacy
Nel 2008 abbiamo avviato una collaborazione con HarperCollins Italia, che ci ha scelto per sviluppare l’e-commerce dei romanzi Harmony.
Nel 2014 insieme al cliente abbiamo deciso di integrare lo shop al sito statico – utilizzato come piattaforma promozionale dei vari brand del gruppo editoriale – e abbiamo scelto di rimodellare l’architettura dell’e-commerce al fine di aumentare le conversioni.
La prima versione di del sito istituzionale eharmony.it era principalmente un sito di gestione dei contenuti. La piattaforma infatti prevede una serie di sezioni editoriali:
- un blog editoriale;
- un blog con contenuti generati dagli utenti;
- una sezione news;
- una sezione letture online, dove editorialmente venivano pubblicate alcune storie.
Altre sezioni invece venivano alimentate da dati importati da un gestionale:
- romanzi;
- autori.
Infine alcune sezione erano pensate per fornire funzionalità varie:
- iscrizione ad un servizio di newsletter esterno;
- ricerca dei contenuti.
Per il tipo di contenuti del sito, eZ Publish rappresentava una buona soluzione, vista la possibilità di creare contenuti custom, una interfaccia di admin già pronta e la possibilità di estendere le funzionalità tramite estensioni e moduli custom.
L’architettura di eZ Publish è di tipo monolitico, come riportato in figura:
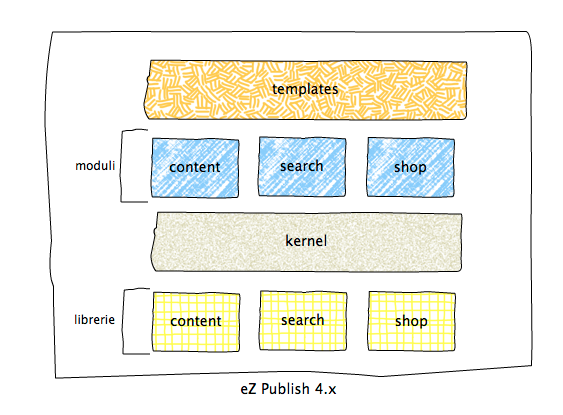
Pur ponendo alcuni vincoli a livello di business, l’utilizzo della piattaforma “as is” ha portato vantaggi in termini di time-to-market. Ciò non toglie che abbia posto alcuni problemi dal punto di vista tecnico:
Testabilità
eZ Publish non è stato pensato con la testabilità del codice in mente e risulta molto difficile scrivere test in isolamento. Variabili globali, singleton, chiamate statiche sono all’ordine del giorno nella codebase, portando ad un pattern abbastanza noto ed abbassando la qualità del codice.
Ci siamo concentrati quindi principalmente sui test di integrazione e funzionali. Ispirandoci a quello che hanno fatto altri framework, abbiamo sviluppato:
- un componente per caricare dati di test: leggendo file in formato yaml si occupa di creare il db e caricare i dati, portando il sistema in uno stato noto;
- un browser per navigare le pagine: in modo da simulare l’interazione dell’utente con il sito.
In questo modo siamo perlomeno riusciti a scrivere una serie di test che preservassero il comportamento del sistema e le funzionalità implementate. Nonostante questo la build del progetto è risultata da subito particolarmente lenta, costringendoci ad accorgimenti vari per velocizzarla.
Logging
Molte funzionalità sono fornite dalla piattaforma ed il logging di informazioni aggiuntive è una operazione complessa. È possibile in linea di principio sostituire o estendere le classi ma con il rischio di rendere più complessa la procedura di upgrade.
Debugging
Nel caso di bug i test, essendo ad ampio spettro, aiutano solo in parte ad identificare le cause. Diverse parti dell’ecommerce utilizzavano il modulo workflow di eZ Publish per eseguire azioni al verificarsi di determinati eventi nel sistema. Sebbene molto potente questa parte è risultata parecchio complessa da debuggare.
Performance
Al crescere del numero di utenti alcune parti del sistema hanno iniziato a mostrare limiti di scalabilità, ad esempio:
- i moduli di reportistica degli acquisti, che non lavoravano su dati precalcolati;
- il modulo di ricerca standard fornito da ez.
Il (ri)lancio della piattaforma ci ha dato modo di fare alcune modifiche strutturali che sarebbe stato complesso portare avanti in maniera incrementale. In particolare abbiamo deciso di:
- continuare ad utilizzare eZ Publish come piattaforma ma solo per la gestione dei contenuti, evitando scorciatoie che alla lunga hanno portato vari problemi,
- disaccoppiare le varie parti del sistema creando moduli custom per guadagnare in testabilità, osservabilità, manutenibilità.
I test scritti ci hanno permesso di andare a fare delle modifiche senza introdurre regressioni sulle funzionalità.
La nuova architettura dell’applicazione ricalca la figura seguente:

Ad oggi i nuovi sviluppi che non riguardino la gestione dei contenuti in senso stretto seguono tutti la strada custom. Lo stesso sistema di raccomandazioni è stato implementato come modulo personalizzato.