
Nata nel 2015, LeadsBridge ha sviluppato l’omonima piattaforma per la lead generation, usata da migliaia di aziende per integrare le principali piattaforme pubblicitarie come Facebook, Google e LinkedIn con i propri CRM, rispettando le normative sulla privacy. Le integrazioni di LeadsBridge consentono di sincronizzare i lead generati sulle piattaforme social con il proprio CRM o di creare, sulla base dei dati di prima parte, audience in target per le campagne sui social, o ancora integrare nel flusso di dati utilizzati per le campagne online le conversioni generate offline.
L’infrastruttura su cui poggia la sua piattaforma applicativa è completamente su AWS, è stata creata ed inizialmente configurata in totale autonomia dal team dedicato dell’azienda stessa.
La collaborazione tra Leadsbridge e Flowing è nata dopo esserci conosciuti all’AWSome Day del 2019 in cui abbiamo organizzato e tenuto alcuni talk che hanno attirato l’attenzione di Leadsbridge, che ci chiese la disponibilità per un’attività iniziale conoscitiva e di potenziale consulenza.
La prima collaborazione si è concretizzata con una prima sessione esplorativa – un assessment dell’infrastruttura – che ci ha consentito di raccogliere il maggior numero di informazioni e dettagli sullo stato dell’arte dello stack applicativo di Leadsbridge su AWS, producendo successivamente un documento contenente una serie di proposte operative e architetturali in ottica di miglioramento ed evoluzione.
Si parte: l’assessment dell’infrastruttura
L’assessment rilevò che alcune parti dell’infrastruttura potevano essere migliorate o ripensate, ad esempio attraverso queste azioni:
- messa in sicurezza di istanze EC2 esposte direttamente ad Internet;
- decoupling dei servizi (alcuni in esecuzione sulla stessa istanza);
- implementazione dell’Automating Scaling dei componenti dell’infrastruttura relativi al tier applicativo;
- riconfigurazione in alta affidabilità (HA) di alcuni servizi;
- refactoring di CronJobs da processi pianificati su EC2 Linux a Scheduled Task su container utilizzando ECS o EKS come orchestratore;
- progettazione di un piano di Disaster Recovery;
- transizione da una gestione “manuale” dell’infrastruttura ad una gestione automatizzabile e riutilizzabile tramite strumenti e processi di Infrastructure as Code (IaC).
Migliorare l’infrastruttura core
Soddisfatta dall’attività di assessment iniziale che avevamo effettuato, LeadsBridge ha deciso di continuare la collaborazione con l’obiettivo di mettere in pratica le nostre proposte operative.
Abbiamo attivato un contratto in modalità “Soddisfatti o Rimborsati”, secondo il quale le attività da fare vengono organizzate in iterazioni (di durata prestabilita decisa tra le parti, ad esempio di una settimana), così da permettere a Flowing di concentrare le energie su specifici task e obiettivi di ogni iterazione e a LeadsBridge di avere il controllo sull’andamento del progetto.
Le prime iterazioni erano focalizzate sulla parte network dell’infrastruttura applicativa, applicando le seguenti modifiche:
- Istanze EC2 applicative su subnet privata ed aggiunta di un NAT gateway per il loro accesso ad Internet.
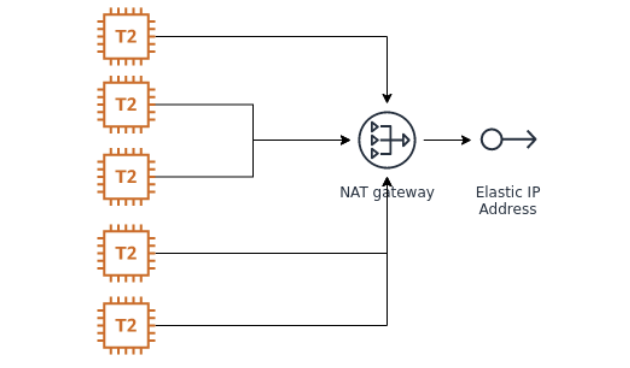
- Collegamento alle istanze EC2 applicative tramite Bastion/Jump Host + VPN Client.
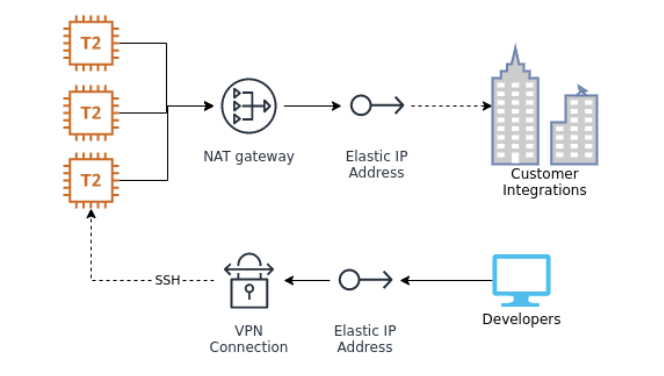
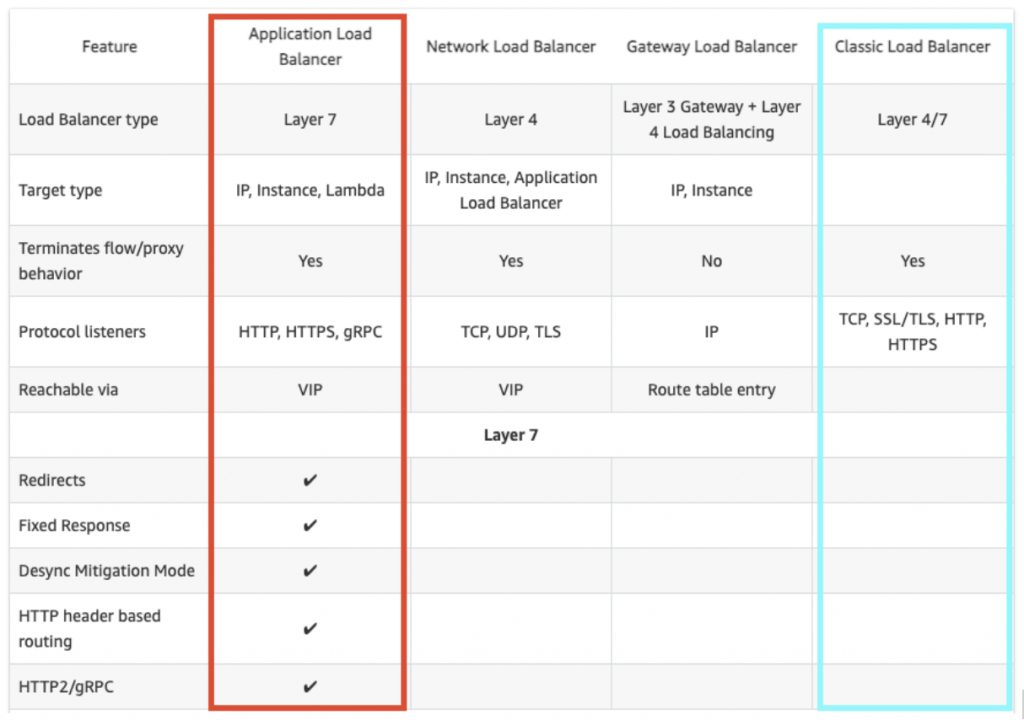
- Migrazione da “Classic” Load Balancer (V1) ad Application Load Balancer (V2), per utilizzare la nuova generazione di bilanciatori applicativi, specifici per il solo traffico HTTP(S), si mettono a disposizione molte funzionalità utili allo sviluppo e test dell’applicazione, ad esempio i redirect basati su header HTTP.
Containerizzare le applicazioni
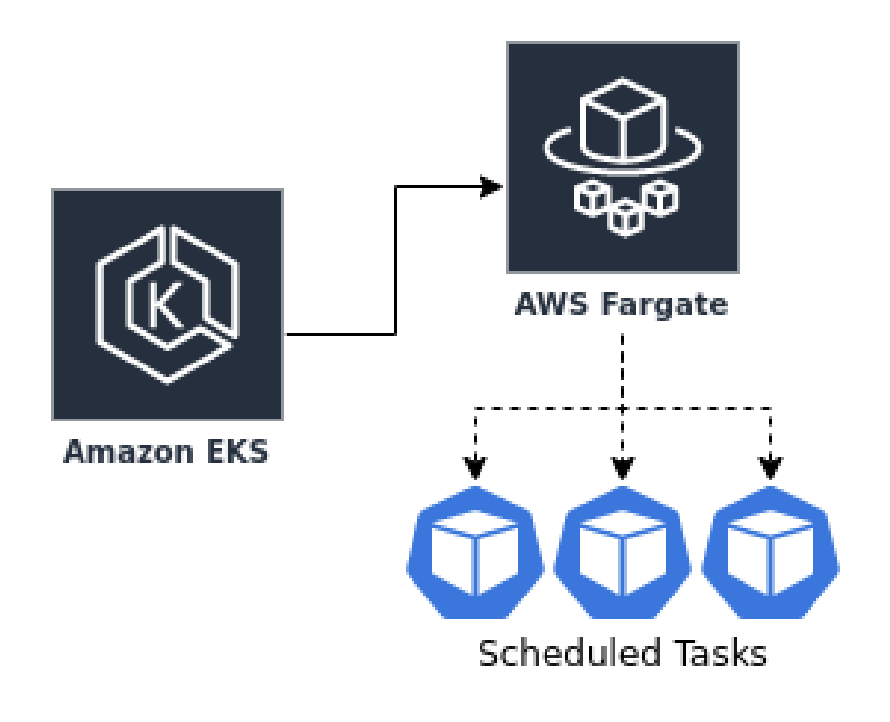
Nelle successive iterazioni il focus si è spostato sul refactoring del componente applicativo demandato all’esecuzione dei task pianificati (cronjobs). Questi task venivano eseguiti sul singolo nodo e portavano le macchine a saturare le proprie risorse e a contendere fortemente le strutture di sistema (RAM, CPU, disco, etc.). Inoltre era presente una suddivisione tra utenti “Enterprise” e utenti “Non-Enterprise” per i quali venivano dedicati dei nodi specifici con diversa potenza computazionale.
Grazie al mondo a container, Docker unito all’orchestratore Kubernetes ed al servizio managed AWS Fargate, è stato possibile dividere ogni singolo cronjob in un container dedicato ed attivarlo nell’enorme potenza di calcolo messa a disposizione da AWS via Fargate. Questa tecnica ci ha permesso di sfruttare la flessibilità di Kubernetes/Docker in combinazione con un modello di pricing in funzione dell’utilizzo su Fargate.
Infrastructure as Code
Già dalle prime iterazioni si era deciso di non proseguire con una gestione “manuale” dell’infrastruttura ma di scegliere un approccio moderno ed innovativo definitivo “Infrastructure as Code”.
Questa modalità operativa è basata sulla definizione della propria infrastruttura tramite un linguaggio appropriato su file di testo memorizzati e gestiti su un repository di Version Control System (nel nostro caso GIT), utilizzando gli standard operativi e gli strumenti propri dello sviluppo applicativo. La possibilità di modellare la propria infrastruttura come codice e di avere la capacità di progettare, implementare e distribuire l’infrastruttura delle applicazioni con le best practice del software permette di semplificare e velocizzare la gestione e la crescita della propria architettura.
Come framework e strumento per Infrastructure as Code abbiamo scelto Terraform, uno dei prodotti più conosciuti ed utilizzati per il provisioning di risorse tramite codice.
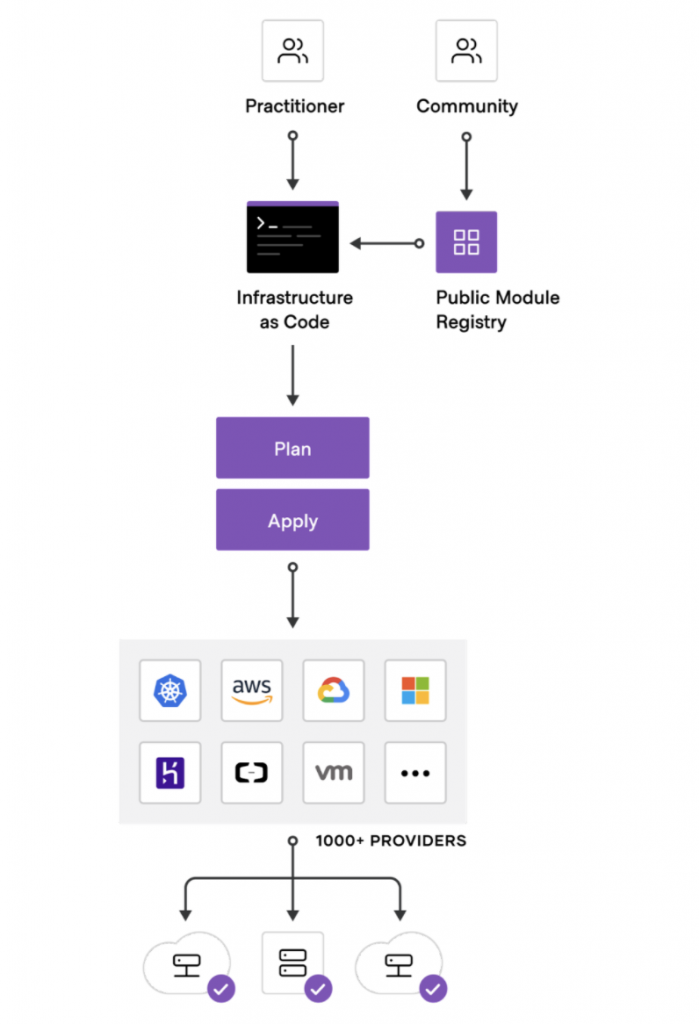
Uno dei punti di forza di Terraform è la sua anima “agnostica”: non essendo legato a nessun provider specifico, è possibile utilizzarlo in molteplici situazioni e con diversi fornitori di servizi. Nel caso di LeadsBridge sono stati utilizzati sia il provider di AWS (per il provisioning delle risorse sull’account di questo cloud provider) che quelli di Kubernetes e di Helm (per il provisioning dello stack applicativo all’interno del cluster EKS). Dove possibile è stato fatto uso dei moduli pubblici presenti su Terraform Registry per riutilizzare codice di alta qualità ed ampiamente testato e ridurre la quantità di codice scritto e da gestire internamente.
Separare gli ambienti
L’infrastruttura su AWS inizialmente predisposta da Leadsbridge risiedeva su un singolo account, contenente sia l’ambiente di produzione che quello di sviluppo/staging.
La suddivisione degli ambienti avveniva utilizzando due differenti VPC, permettendo di isolare le risorse a livello di rete. Questa soluzione è una delle più semplici ed efficaci per ospitare più ambienti di lavoro in un singolo account, ma introduce alcuni elementi negativi:
- per mantenere un’efficace differenziazione delle risorse, anche a livello di fatturazione, è necessario applicare una naming convention ed una strategia di tagging corretta;
- il controllo degli accessi e dei permessi tramite IAM risulta difficile da gestire e limitare in quanto non è possibile applicare filtri e condizioni per diverse azioni a livello di singola risorsa (per esempio non è possibile limitare “ec2:describeInstances” a delle singole istanze EC2);
- Gli account AWS sono limitati a 5 VPC per regione, limitando di conseguenza il numero di ambienti (o progetti) utilizzabili nello stesso account.
Abbiamo deciso di applicare la strategia comunemente utilizzata (e consigliata da AWS stessa) di separare i diversi ambienti di lavoro in account dedicati, ed utilizzare il servizio AWS Organizations per centralizzare la gestione di più account, suddividendoli in unità organizzative con la possibilità di applicare policy e configurazioni globalmente.
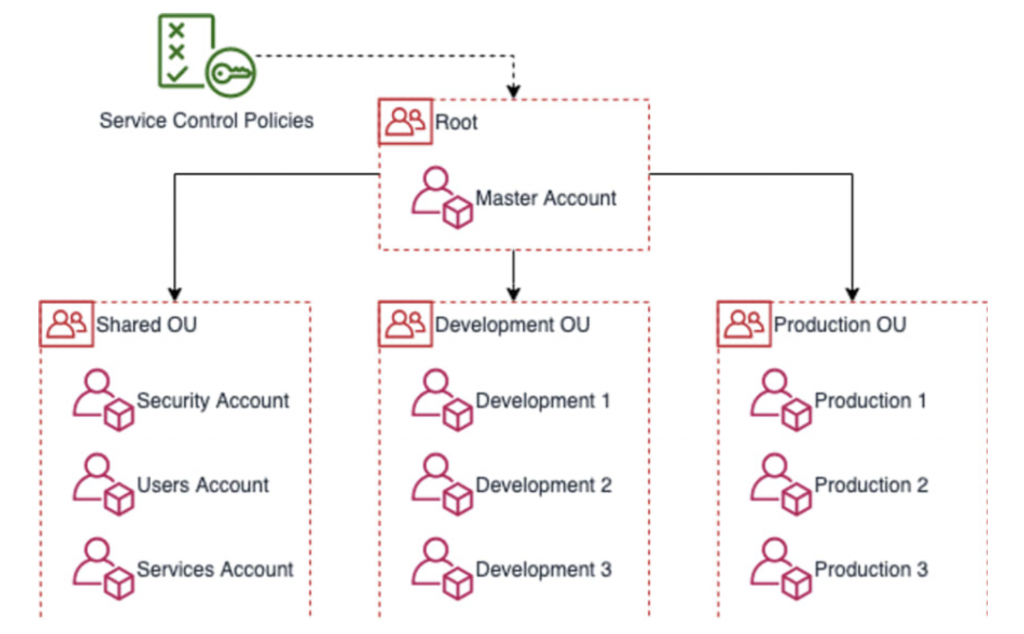
Abbiamo quindi creato un nuovo account per l’ambiente di staging, nel quale è stata replicata l’infrastruttura presente in produzione (attività semplificata grazie alla precedente attività di “Terraform-izzazione” delle risorse). Avendo due account ed ambienti separati per mettere in pratica strategie “Git* Flow” di deploy sia applicativo che infrastrutturale, permettendo al team di sviluppo e di operations di applicare e testare modifiche agevolmente in staging e “promuovere” i cambiamenti in produzione in modo controllato.
Automatizzare Scaling e Deployment
Una delle componenti applicative gestite da un pool manuale di istanze EC2 presentava carichi di lavoro che potevano essere ottimizzati. Nello specifico si riscontravano carichi uniformi nelle zone di comfort delle istanze.
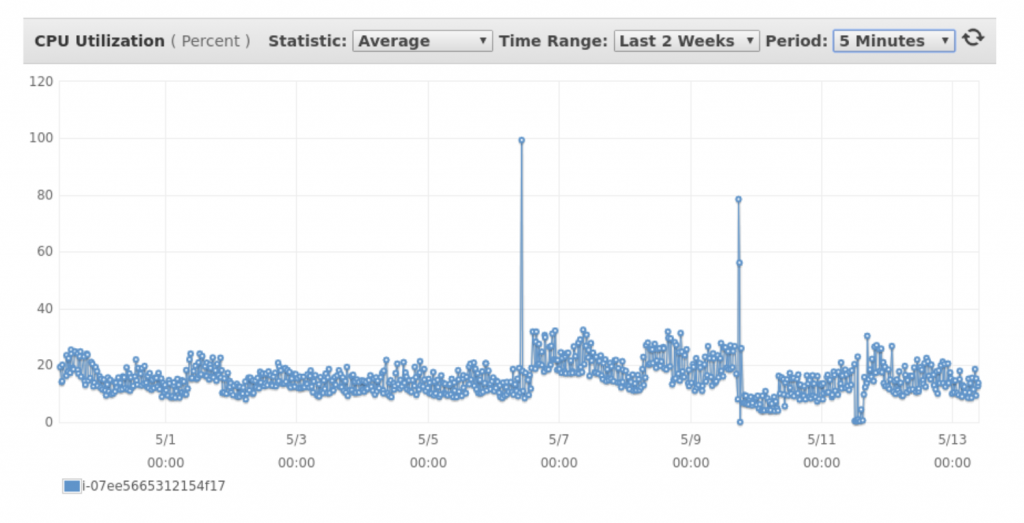
Inoltre la configurazione manuale del pool di istanze (registrate manualmente nel rispettivo Target Group agganciato all’Application Load Balancer) rendeva difficoltosa la loro attività di manutenzione, soprattutto in casi di disservizio (ad esempio una delle istanze andava in errore e richiedeva un intervento manuale per essere ripristinata).
Abbiamo introdotto il servizio “Autoscaling” che permette di ottimizzare il modello di pricing (pagare per quello che si consuma realmente): rende possibile lo scaling orizzontale, sostenendo un forte incremento dei piani di espansione del business, ed assicura che la quantità desiderata di istanze sia sempre in esecuzione in caso di disservizi o degradazioni sulle zone di disponibilità delle region di AWS.
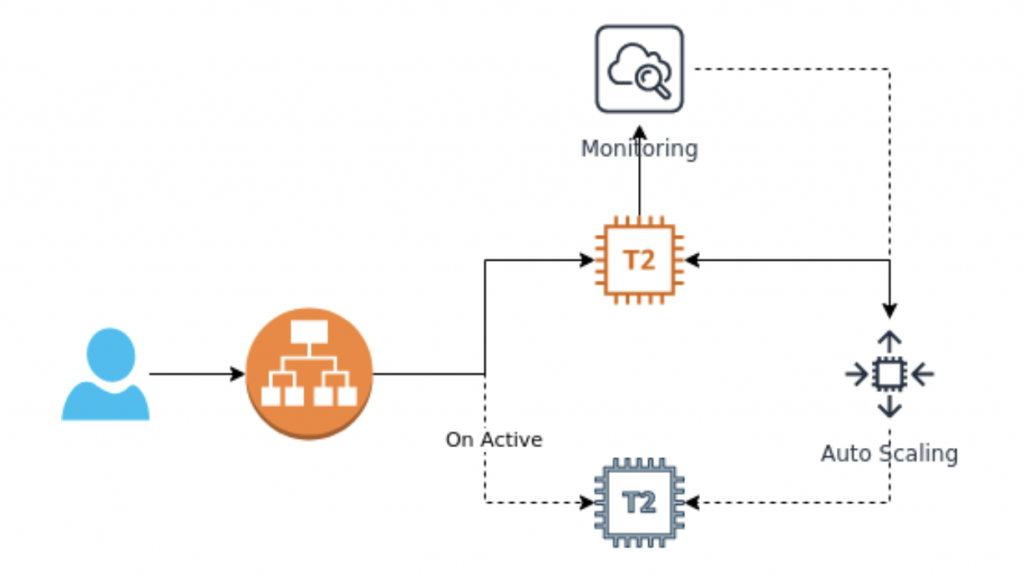
Abbiamo inoltre migliorato la strategia di deploy dell’applicativo all’interno delle istanze, precedentemente gestito tramite degli script custom pianificati all’interno delle stesse, in quanto mancavano sia degli strumenti per tracciare e controllare adeguatamente i rilasci delle nuove versioni sia la possibilità di effettuare un veloce rollback in caso di problemi.
Il servizio scelto per soddisfare questi requisiti è stato AWS CodeDeploy, che si integra facilmente col servizio di repository Git e pipeline utilizzato da Leadsbridge, ovvero Bitbucket (Repository e Pipelines), utilizzando Amazon S3 come servizio di storage delle revisioni applicative.
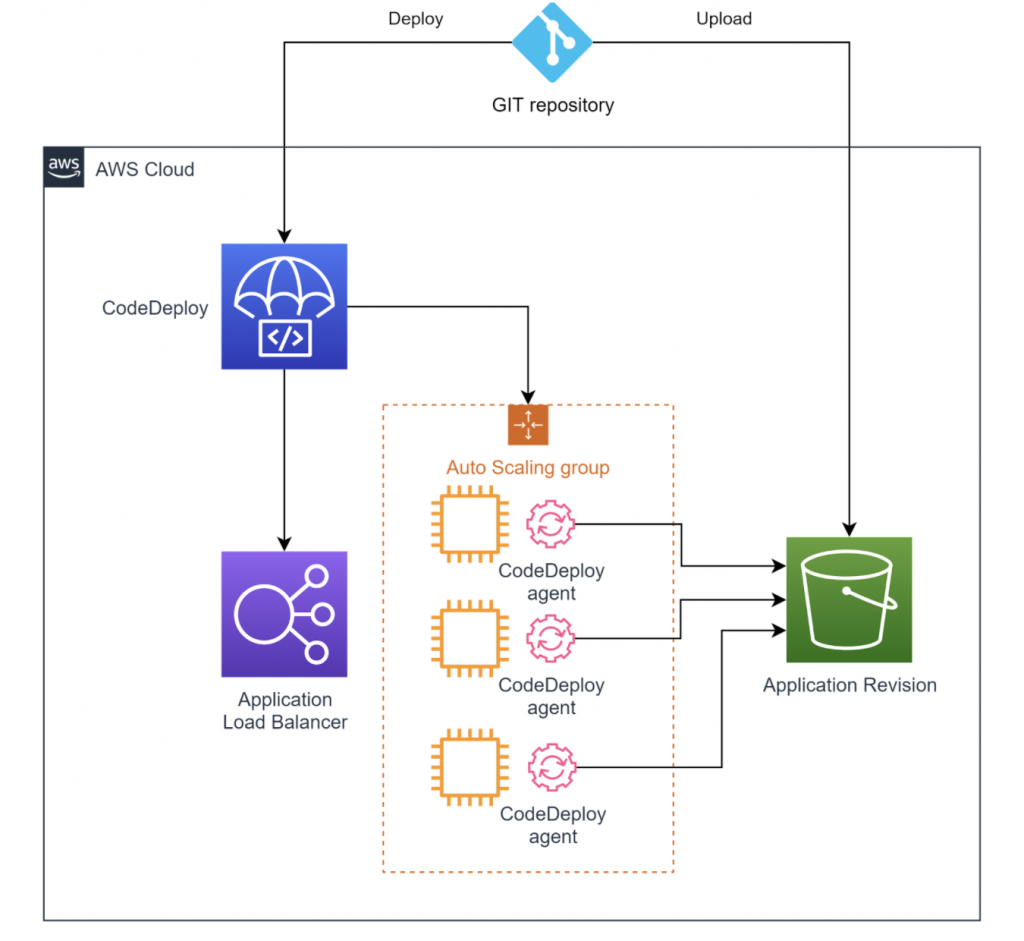
Grazie ad AWS CodeDeploy i rilasci del codice applicativo all’interno delle istanze EC2:
- vengono avviati automaticamente dalla pipeline di CI/CD a seguito del merge nella branch di riferimento (Automated Deployment);
- vengono applicati alle istanze riducendo al minimo o annullando il periodo di downtime dell’applicazione, utilizzando le tecniche di “rolling update” o “blue-green deployment” (Minimize Downtime);
- possono essere annullati, ripristinando la versione precedente, in caso di errori o problemi (Stop and Roll Back);
- vengono versionati e tracciati all’interno dell’interfaccia di gestione di CodeDeploy (Application Revision).
In sintesi
Grazie al nostro supporto, Leadsbridge è riuscita a migliorare sensibilmente la qualità della propria infrastruttura applicativa, rendendola maggiormente gestibile e scalabile, ottimizzando i costi, e creando le basi per ulteriori evoluzioni architetturali, rese possibili grazie alla vasta gamma di servizi messi a disposizione da Amazon Web Services.
Flowing ci sta aiutando ad ottimizzare l’infrastruttura AWS, modernizzandola e adattandola ai più recenti standard di sicurezza, adattandosi alla nostra metodologia di lavoro ed offrendoci supporto e cooperazione in un team in crescita. Abbiamo da subito apprezzato il loro training-on-the-job. Siamo diventati fin da subito un team unico di lavoro e grazie a questo siamo riusciti a completare diversi obiettivi.
Stefano Pedone, Devops Engineer